Raft 算法理解和总结
Hyperledger fabric 自1.4.1版本开始支持了 Raft 共识,比原先的生产环境推荐共识”kafka”,搭建的复杂度和可维护性上要好不少,并且 1.4.0 是 Hyperledger的第一个长期维护版本(long term support),推荐在生产环境中使用,完全可以升级并使用Raft共识。
本文介绍总结Raft 算法,主要是根据著名的 Raft讲解动画的理解,并进行文字化的总结。强烈推荐这个讲解动画,可配合动画阅读下文,更容易理解。
概念
Raft 算法中的三种角色:
follower 追随者,普通节点默认都是follower
candidate 候选人,当准备发起新一轮选举的时候,由follower升级而成,选举完成会变回follower或成为leader
leader 领导者,即候选人被选中上,成为主节点
Raft 算法中的两种超时
election timeout - 选举超时
选举超时,即 follower 等待成为 candidate 的超时时间,一般在 130ms~300ms 之间。
在follower 开始倒计时 election tomeout 时间后,开始成为candidate,并且发起一次选举过程。
heartbeat timeout - 心跳超时
leader 会在heartbeat timeout 后发送心跳包,这也就是leader发送心跳包的时间间隔。
流程
同步数据的过程
 这个过程叫做日志复制(Log replication)
这个过程叫做日志复制(Log replication)
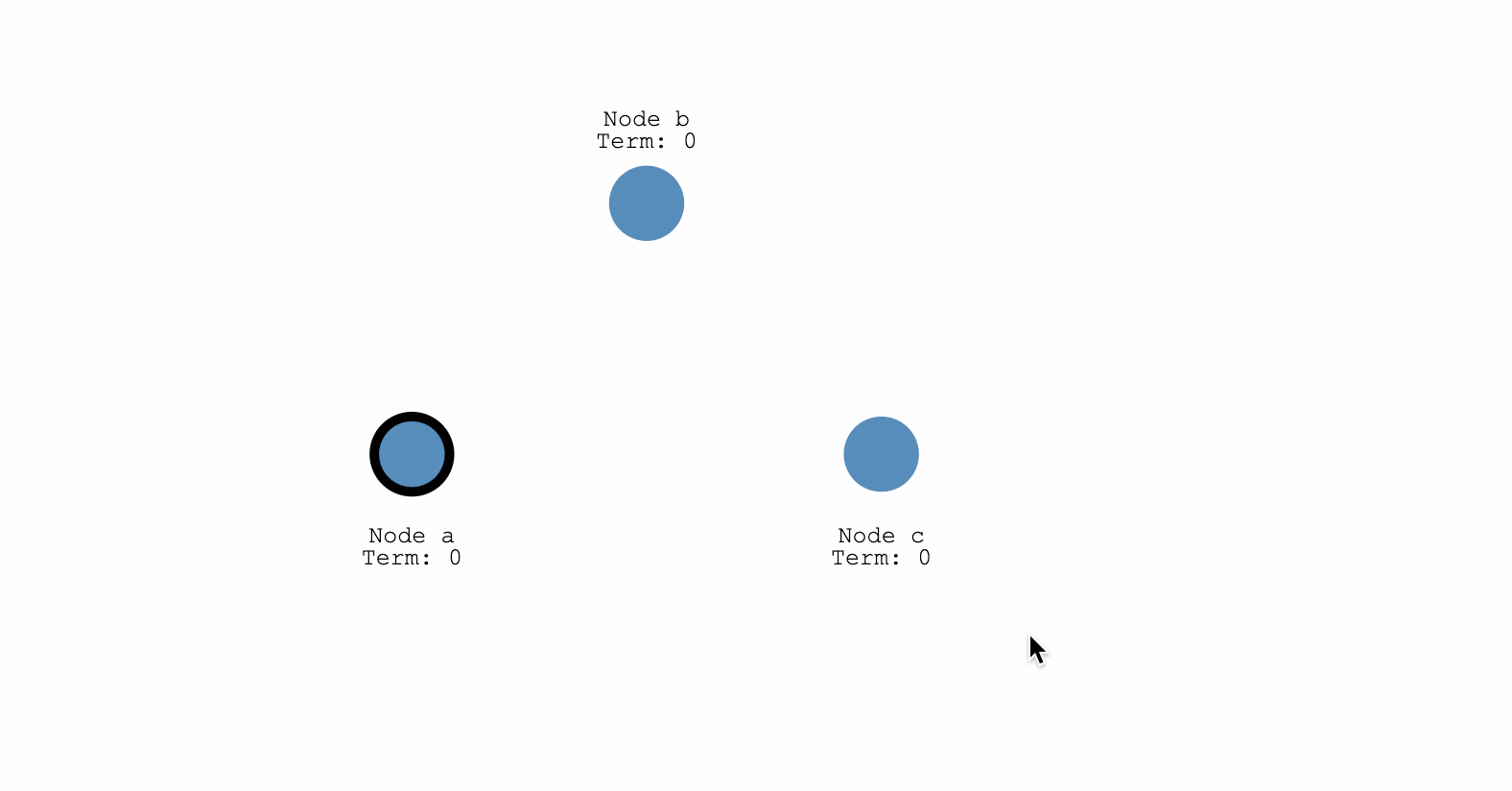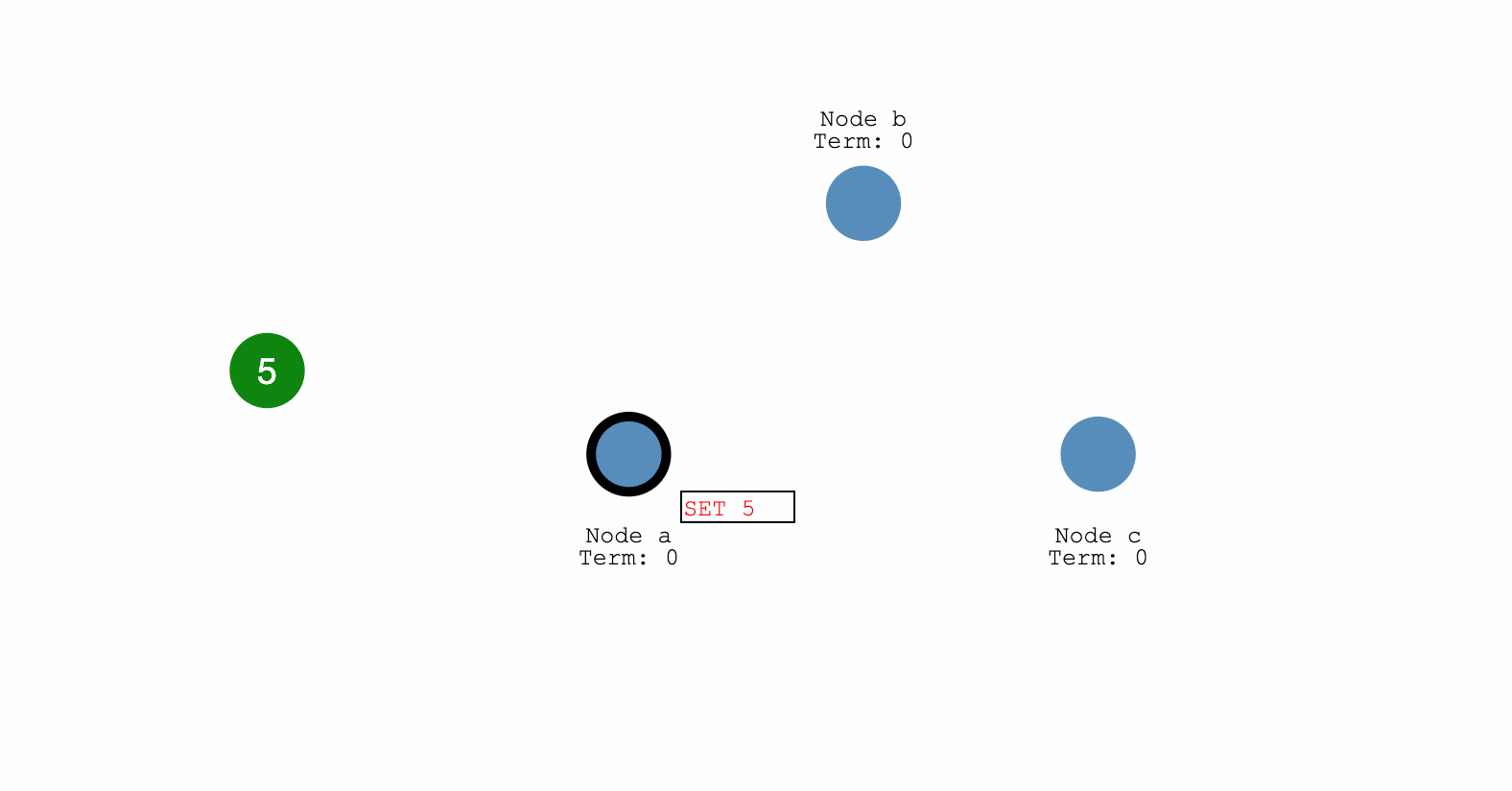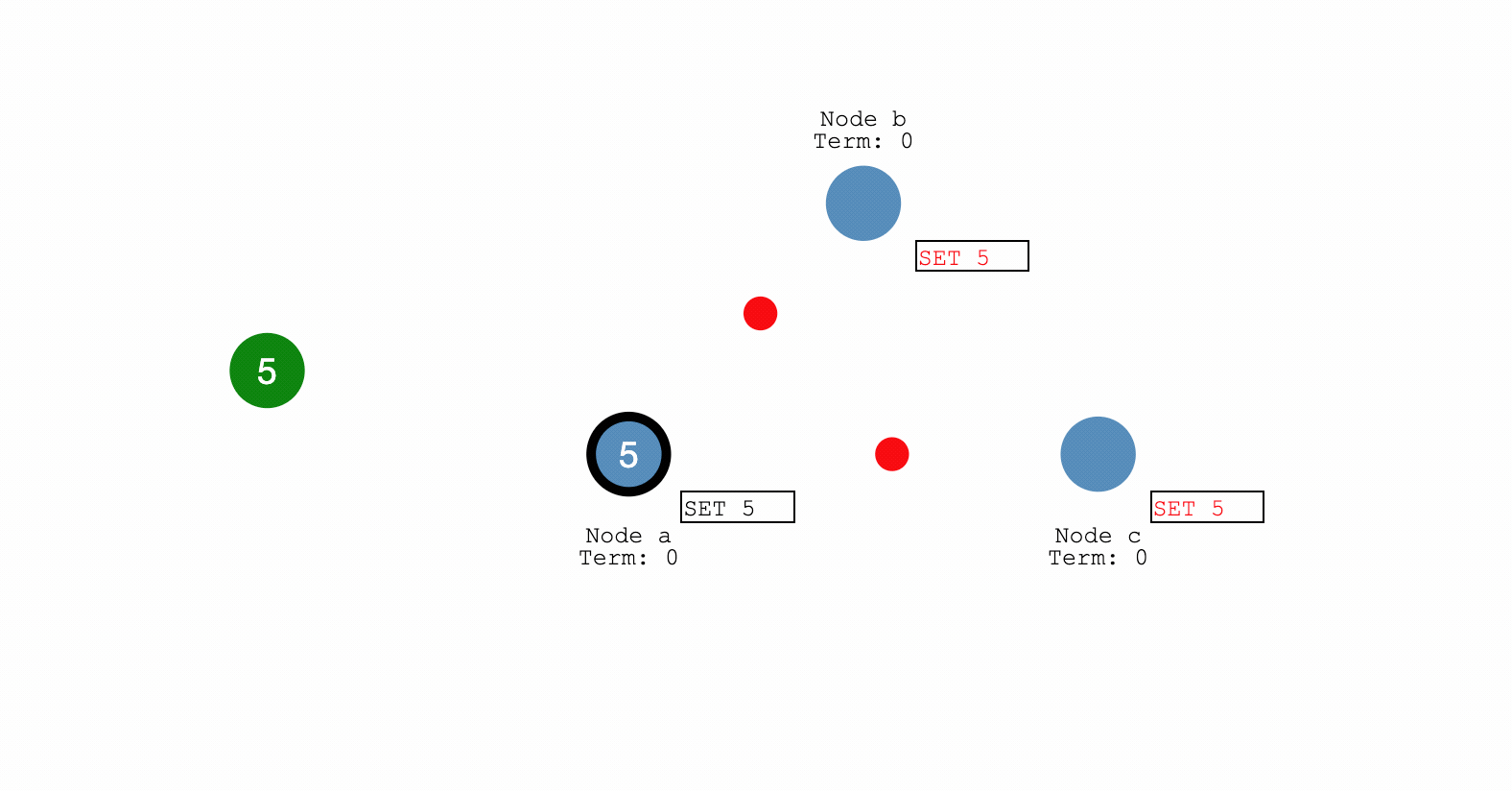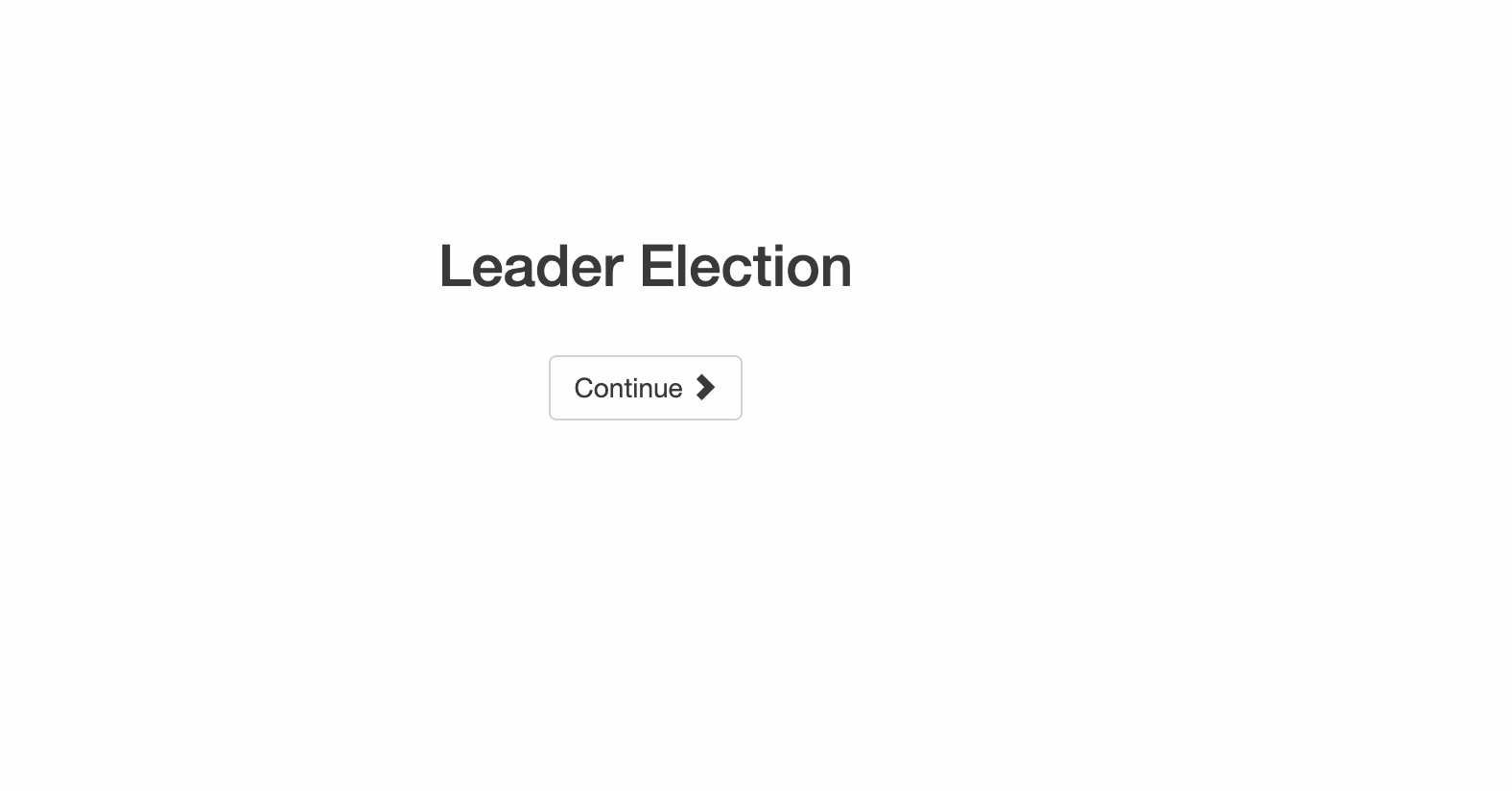
- client 向系统发送(会导向leader节点)更改消息
- leader 预修改数据,但不commit(未确认修改)
- leader 向follower,发送修改消息
- follower 回复 ack,并且预修改这个消息,但不commit
- leader收到这个ack之后,首先进行commit(确认修改),并且发给client
- leader 向 follower发送心跳包,携带leader已commit这个消息
- follower收到leader的已commit消息,知道leader已经commit了,那么自己也进行commit
开始选举的过程

candidate首先给自己投一票,然后发送消息给其他节点,请求其他节点的选票
如果这时候,这些 follower 节点还没在这轮选举中投过票,那么会投这个 candidate,然后重置自己的 election timeout。上文提到follower 在倒计时election timeout后发起新一轮选举,那么这时因为重置了 election timeout,所以是不会发起选举的,维持了节点的follower特性。
candidate 收到足够的选票,成为 leader
leader 发送心跳包
leader 会在每间隔 header timeout 给每个folloer发送一个心跳包,称为Append Entries
只要follower能收到心跳包,则维持这次的选举结果(重置election timeout?),继续当一个follower
异常情况的处理
同时成为candidate,导致分裂选举的情况
因为 election timeout 是各自在 150~300 随机的,出现同时达到的情况概率较低,但仍有可能。
- 两个 follower 同时达到 election timeout,同时成为 candidate
- 两个 candidate 各自给自己投一票,并且同时发送选举请求给其他的follower
- 因为其他 follower 只对这轮选举投一个,所以,如果有两个follower(或者说偶数),则可能出现,每个candidate收到一个follower(或者说收到的选票相等),那么选举无法完成。
- 选举无法完成,两个 candidate 再间隔一段时间后(election timeout重新随机了一次,再次同时的概率更低了,这也是为什么election timeout是个范围值而不是固定值),继续发起新一轮的选举。
- 如果这次没有再出现两个人收到的选票一样的情况,那么,选票多的candidate当选leader
- 完成选举后,会对同步leader的数据给follower
如图所示: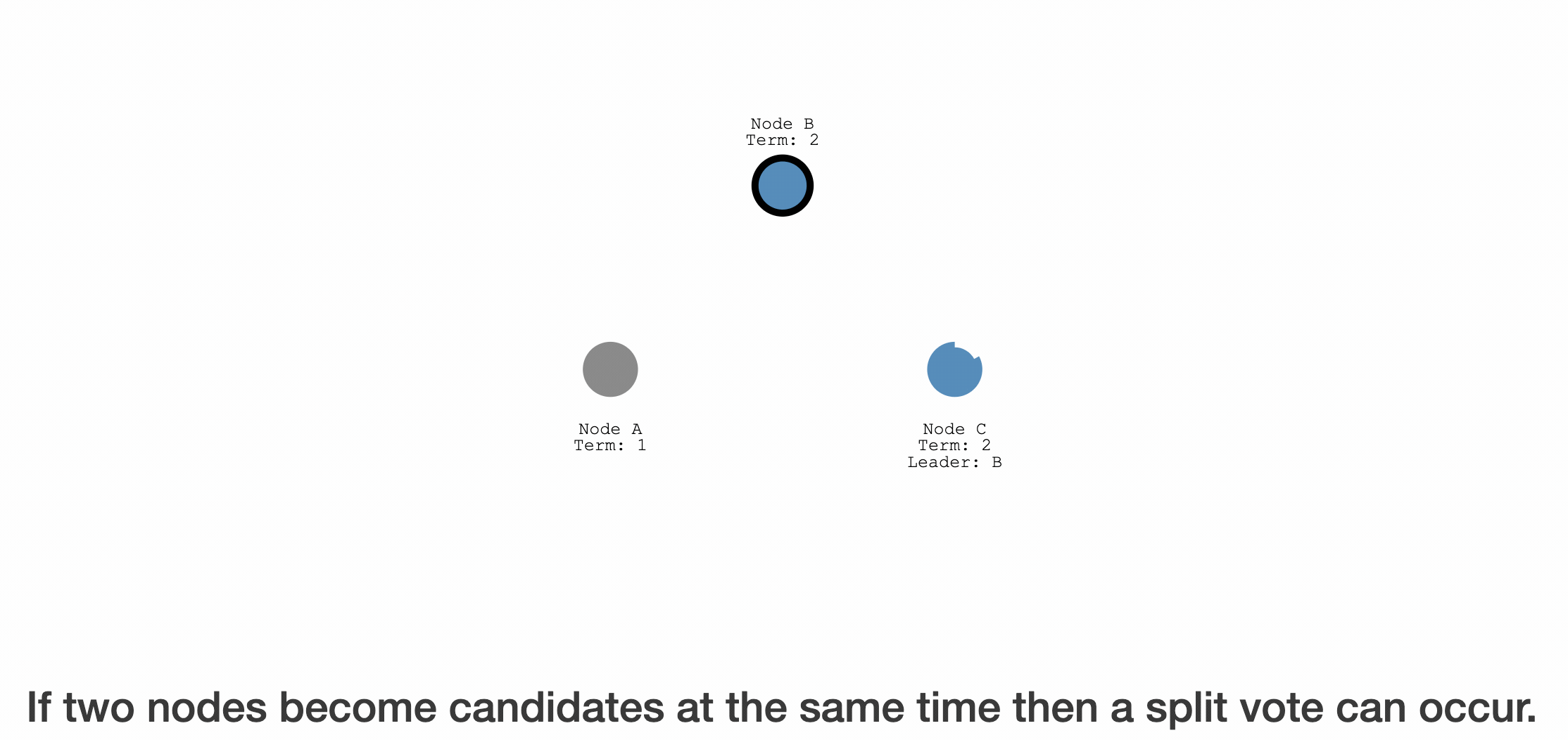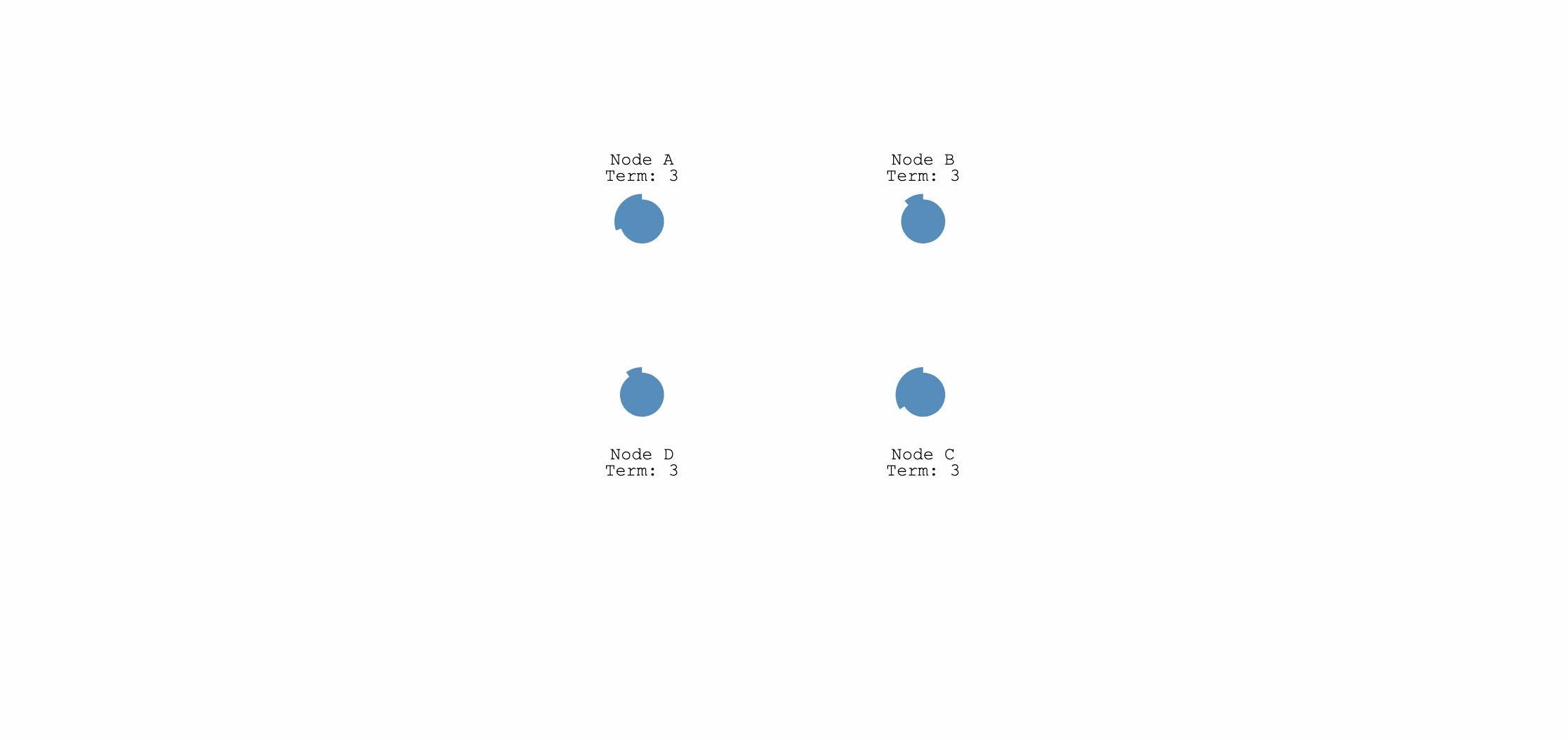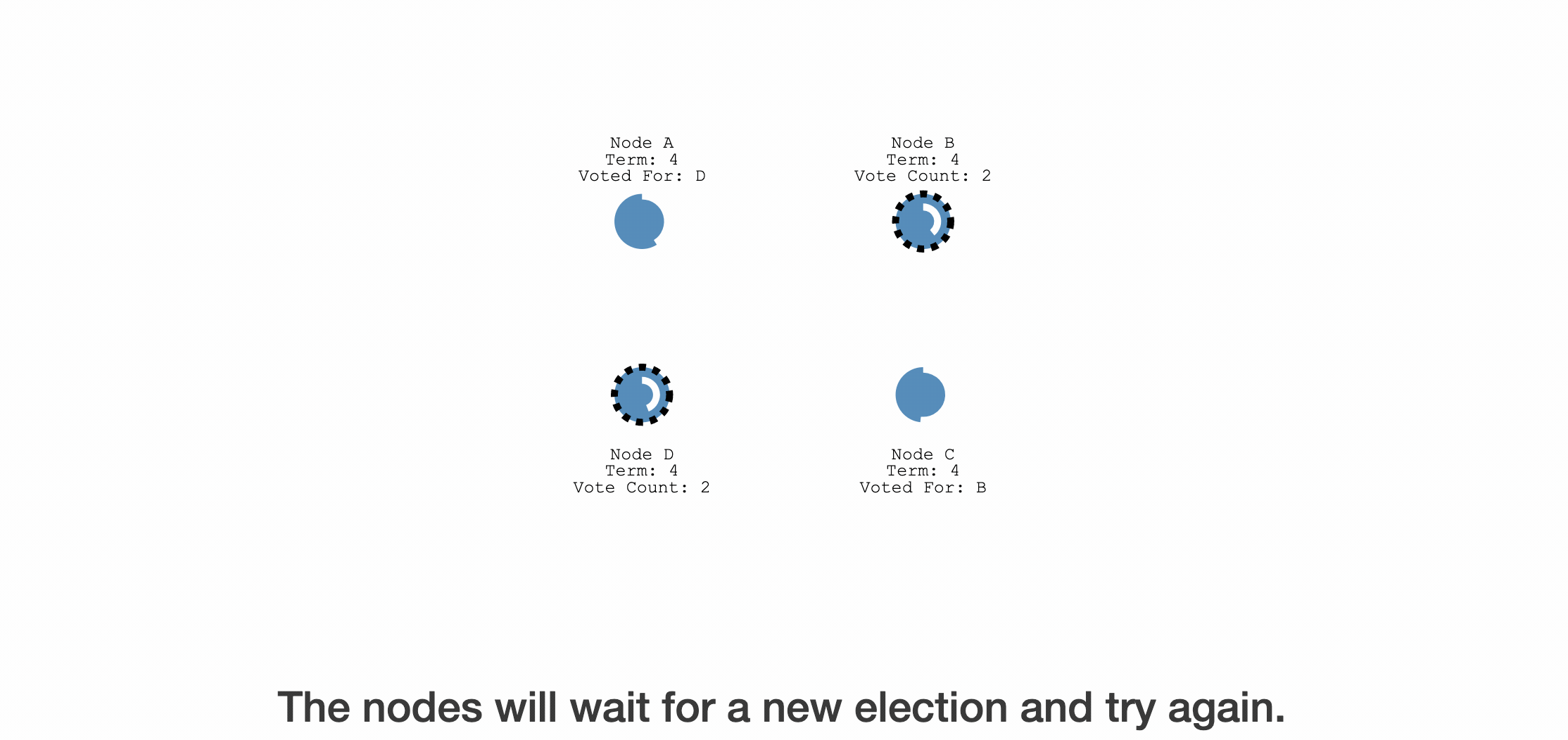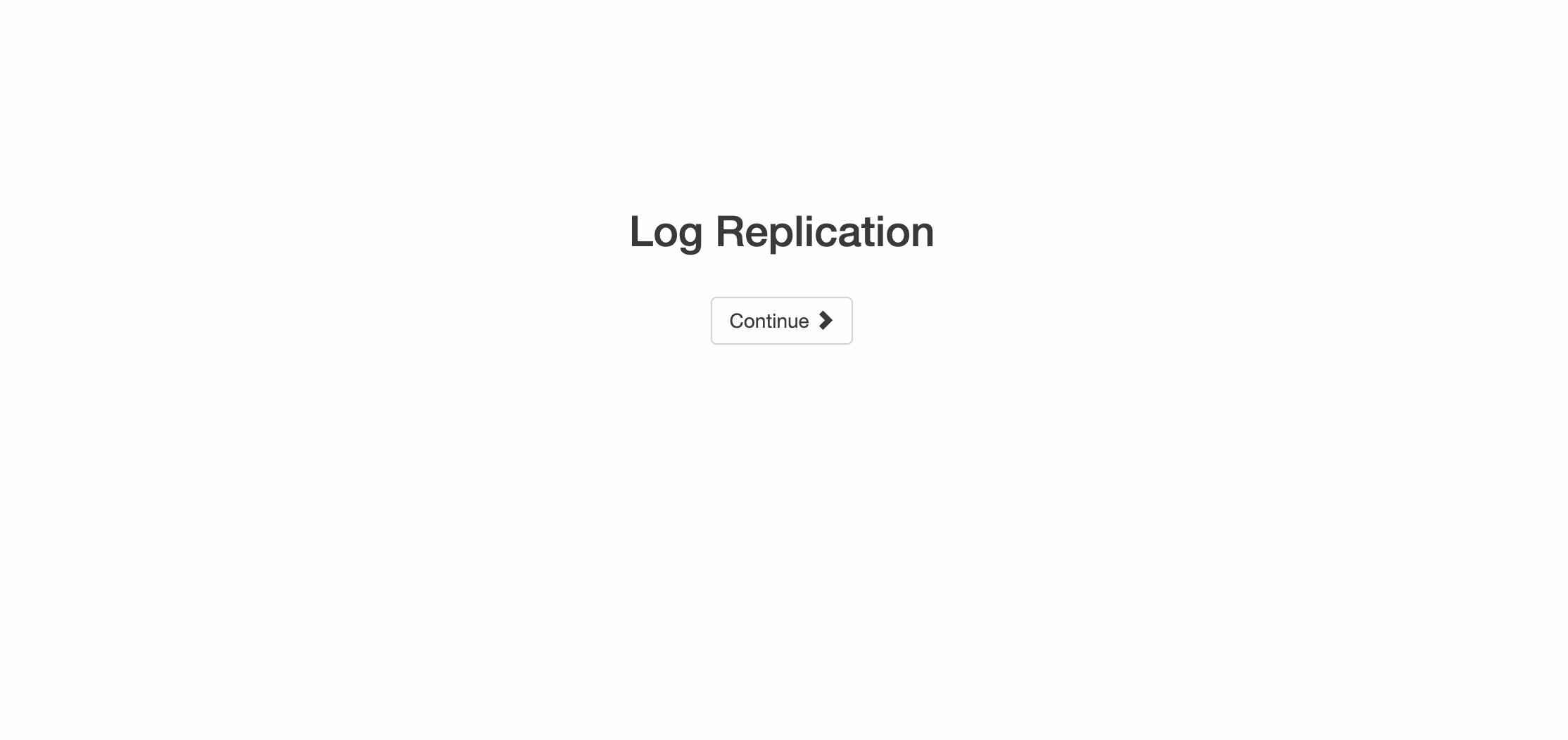
出现网络分区时怎么做?
异常情况出现了,假设存在五个节点,node A~E,B是leader,这时候因为网络分区,node A和B可互通信,但其他节点已经联系不上AB节点,那么就会出现两个分区,一边三个节点,一边两个节点。如图所示:
这时 CDE 节点没有leader,会发起新的选举,直到从中选中新的leader。他们的选举轮数肯定是递增的(比AB的大)。
- 如果客户端访问到的是 AB的分区,那么按如下流程:
- leader(B) 把数据发给 folloer (A)
- A 接受到数据,数据处于未提交状态,并发个ack给leader(node B)
- B 只收到了一个回复,远远小于选举时的节点数(4个follower),通知A不要commit
AB的数据一直属于未提交状态(uncommited)。
- 如果客户端访问到的是CDE的分区,那么按如下流程:
1.leader 把 数据发给 follower们
2.follower 收到并回复 ack
3.leader 收到大多数follower的ack,决定更新数据,并告知follower们也更新数据
这时候,如果网络故障修复,消除了网络分区,那么因为 CDE节点所在的分区,选举轮数(term)比较大,所以AB所在分区会回滚掉中断之后的修改,而是以CDE分区的数据为准。并且以 CDE 的leader 为统一的leader
如何保证leader的数据是最新的呢?
因为 candidate 当选leader后,会让底下的follower同步他的数据,那么就必须保证他的数据是最新的。Raft 通过如下机制保证 candidate 的数据是最新的:
candidate 在发送 RequestVote 请求follower 给自己投票的时候,把自己当前最新的log 的index 和 term(选举的轮数)发给 follower,follower收到后如果发现自己本地的数据比candidate还新,那么拒绝投票。
比较新旧的依据是, term 大的比term小的数据更新,如果 term一样,则 log index大的数据更新。